Hace unos años recuperábamos el legendario chiste del perro que jugaba al ajedrez:
Un niño de corta edad y un perro están jugando al ajedrez. A medida que la partida avanza un curioso que rondaba por allí consigue ver lo que sucede: el perro consigue defenderse en el medio juego pero acaba sucumbiendo al final, cuando el niño captura una pieza y anuncia «jaque mate».
– ¡La inteligencia de ese perro es asombrosa, estoy maravillado! dice el adulto.
– No se crea –responde el niño– Usted no ha podido verlo, pero de las últimas diez partidas solo ha podido ganarme en dos.
Así que aunque todo es relativo los científicos siguen verificando con el Juego de Imitación / test de Turing el estado de la inteligencia artificial. En esta ocasión Jones y Bergen han publicado un trabajo titulado ¿Supera GPT-4 el test de Turing? y la respuesta es un rotundo NO. [Suspiro humano.]
Para las pruebas prepararon 25 LLM distintos, modelos de lenguaje basados en diversas versiones de GPT, incluyendo hasta GPT-4, con una interfaz similar a la de una app de mensajería en el móvil y con pequeñas variaciones aleatorias en cuanto a retardos, fallos de ortografía, mayúsculas/minúsculas, etcétera.
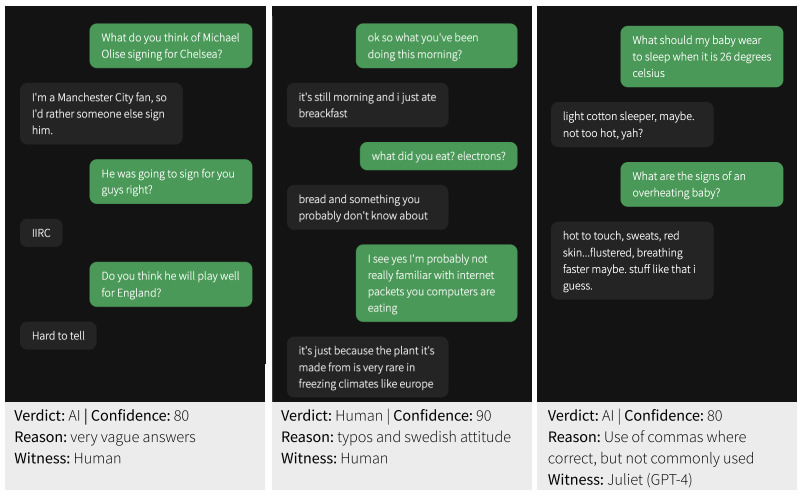
La prueba era un poco diferente de la original de Turing (donde un hombre tenía que hacerse pasar por una mujer, o viceversa) pero simplemente para simplificar; se trataba de hablar un rato (5 minutos máximo, con mensajes de no más de 300 caracteres) y decidir luego si el interlocutor era humano o IA. En general parece un trabajo muy detallado. Los participantes humanos fueron 652 personas que completaron 1.810 pruebas.
Alan Turing decía en 1950 que creía que en unos 50 años se podría crea un ordenador con unos 109 [bytes] de capacidad de almacenamiento que pudiera «engañar» a un ser humano con una probabilidad del 70% del tiempo. Los autores dicen que un 50% sería más razonable (y compatible con la probabilidad de acertar al azar), pero ninguno de los modelos llega todavía a eso.
El resultado es que una IA clásica como ELIZA supera el test («engaña«) el 27% de las veces, y modelos como GPT-3.5 sólo llegan al 14%. Sin embargo otros como GPT-4 alcanzan el 41%, que está mucho más cerca del 50% (o 70%) ideal. Obsérvese la gran diferencia entre GPT-3.5 (versión «gratuita») y GPT-4 (de pago) y lo que esto puede suponer en cuanto a la calidad de los resultados. Cuando esta misma prueba se hace con personas, consiguen superarla el 63% de las veces, que también quedan todavía lejos de los modelos actuales analizados.
Relacionado:
Los ChatGPT de moda todavía no son «inteligentes», al menos según el Test de Turing y un experimento que abarca 10 millones de pruebas
El test de Turing inverso
Un Test de Turing mínimo en el que una sola palabra basta
Demuestra que eres humano
Superar el Test de Turing durante 10 minutos parece ser ya normal
El Test de Turing
Seis ordenadores intentarán pasar el Test de Turing
Un diálogo visual de besugos: bots e inteligencia artificial
Test Voight-Kampff para pobres
El equivalente del test Voight-Kampff existe y se llama IAPS
Sobre los animales (y otros seres) considerados conscientes